[데브인턴십 4기] Between의 Zookeeper 활용
최정재업데이트:
Zookeeper 란?
주키퍼의 기능
지금까지 어떤 프로젝트를 수행해 왔는지 설명했고 지금부터 세부 내용에 대해 설명드리겠습니다. 먼저 ‘zookeeper가 무엇이고 어떻게 작동하는지’입니다.
주키퍼의 핵심 기능 개발자가 사용해야 하는 기능: Tree 구조, Watcher 주키퍼가 보장해주는 기능: 에러 확장 방지, 일관성, 원자성
주키퍼가 제공하는 핵심 기능을 위와 같이 5개로 나타냈습니다. 그리고 이 특징을 ‘개발자가 사용해야 하는 기능’, ‘주키퍼가 보장해주는 기능’ 으로 분류했습니다.
먼저 “개발자가 사용해야 하는 기능”을 보겠습니다.
Tree 구조, Watcher
주키퍼의 data 저장 방식은 tree 자료구조를 사용합니다.
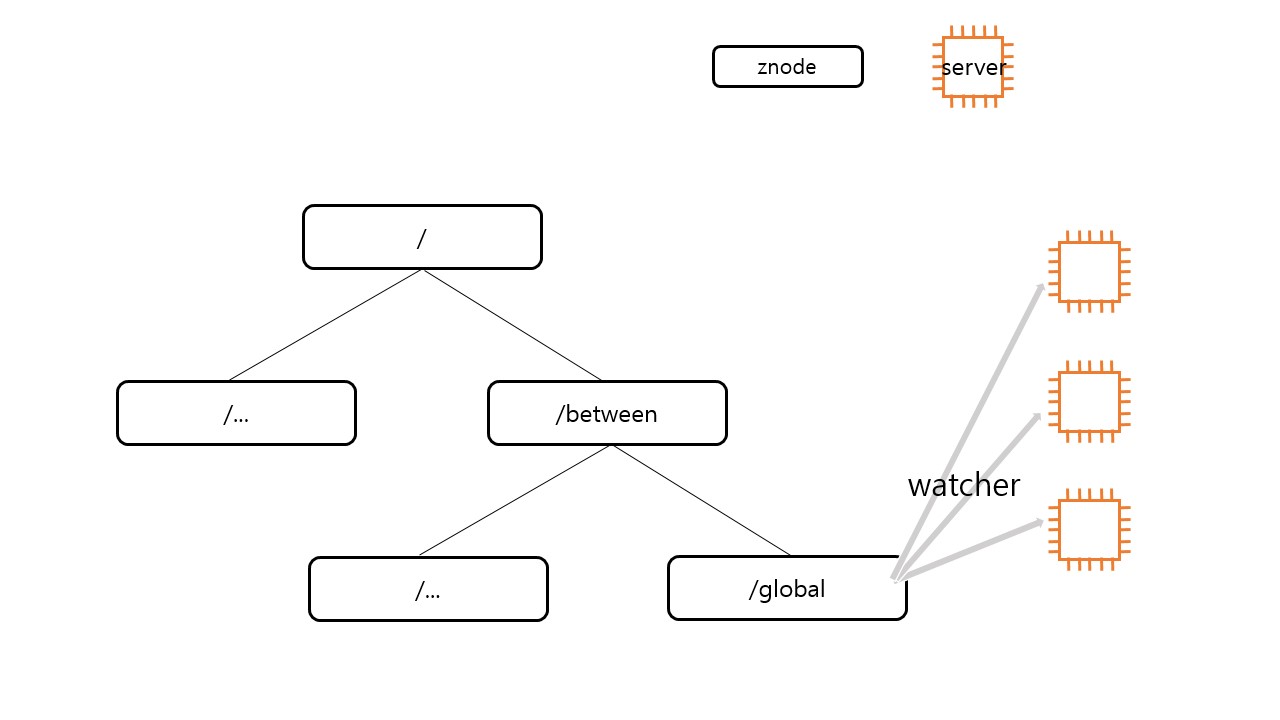
다음은 Between 주키퍼의 구조를 간략하게 나타낸 것입니다. 주키퍼는 node 하나를 znode라고 부르고 있습니다. 개발자들은 server에서 특정 path의 znode에다가 watcher를 등록할 수 있습니다. 해당 znode의 data가 변경,삭제되면 watcher를 통해 서버에서 이 사실을 알 수 있습니다. 그러면 서버는 znode의 data를 다시 읽어와 해당 서버의 data를 최신화 시킵니다. 즉, distribution은 watcher + server의 data 업데이트 logic으로 이루어 진다고 볼 수 있습니다. watcher를 등록하고 watcher에 의해 event가 감지됐을 때 server에서 data를 다시 읽게 하는 callback function을 만드는 것이 개발자가 할 일입니다.
다음으로 “주키퍼가 보장해주는 기능” 을 보겠습니다.
에러 확장 방지, 일관성, 원자성
 출처: https://ssup2.github.io/theory_analysis/ZooKeeper/
출처: https://ssup2.github.io/theory_analysis/ZooKeeper/
다음 그림에서 나타내는 것이 주키퍼 서버 클러스터입니다. 여러 Client가 주키퍼 클러스터에 연결되어 있는것을 보실 수 있습니다. Client는 주키퍼를 통해 config distribute되는 비트윈 서버들이겠죠. 보시다시피 주키퍼 서버는 여러 서버들과 연결되어 있기 때문에 주키퍼 서버에서 에러가 생기면 그 에러는 여러 서버로 퍼져나가게 됩니다.따라서 주키퍼는 주키퍼 서버의 에러를 서버전체로 퍼뜨리지 않기 위한 기능을 제공합니다.
여기서 클러스터의 존재 이유가 나옵니다. 다음과 같이 주키퍼는 주키퍼 서버를 여러개두고 이를 클러스터로 관리합니다. 클러스터내에 과반수 이상의 주키퍼 서버가 살아 있고 같은 data를 반환한다면 해당 data를 통해 일관성을 유지하고 서비스를 지속합니다. 만약에 5개의 서버가 클러스터를 이루고 있을 때 2개의 서버에서 에러가 터져도 주키퍼 시스템은 그대로 유지된다는 것입니다. 이러한 과반수 시스템이 주는 특징중 하나가 클러스터내의 주키퍼 서버를 홀수개로 유지하는게 좋다는 것입니다.
상황을 들어봅시다.
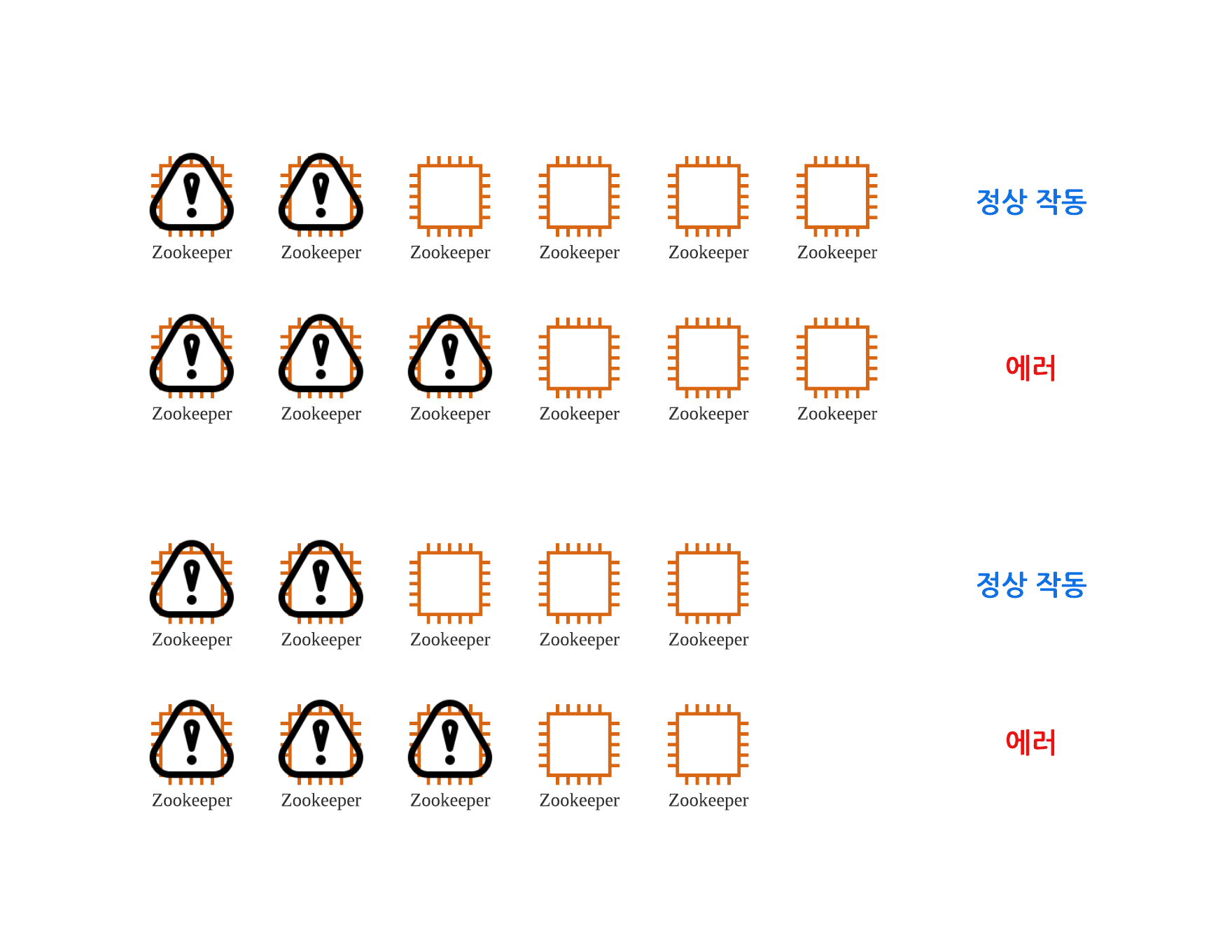
5개의 서버가 있을 때 2개의 서버가 다운되는 것은 문제가 되지 않고 3개의 서버가 다운되는 것은 문제가 됩니다. 과반수이상의 서버가 살아있어야 하니까요. 그런데 6개의 서버가 있을 때에도 2개의 서버가 다운되는 것은 문제가 안되지만 3개의 서버가 다운되는 것은 문제가 됩니다. 따라서 안정성이 똑같으면서 더 적은 resource로 관리가 가능한 것은 홀수개의 서버라는 것입니다. 이 때문에 주키퍼에서도 홀수개의 서버로 클러스터를 구성할 것을 권장하고 있습니다.
주키퍼는 분산처리를 어떻게 하는가?
다음으로 분산 처리가 어떻게 이루어 지는지 설명드리겠습니다.
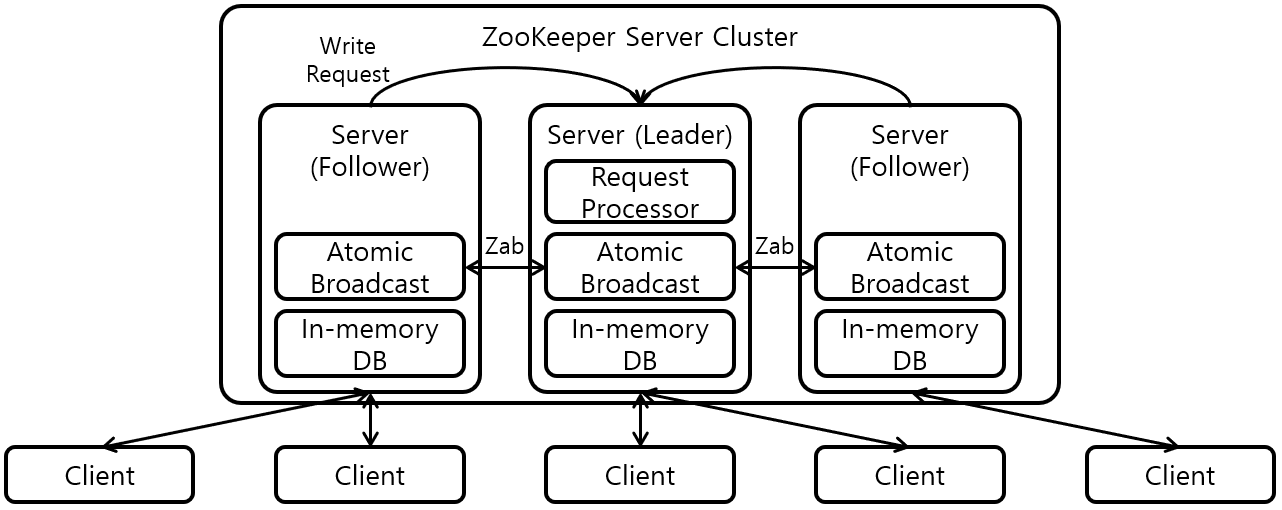
출처: https://ssup2.github.io/theory_analysis/ZooKeeper/
- client의 update 요청
- 팔로우 서버는 update 요청을 리더 서버로 넘김.
- 리더 서버에서 data update가 일어남. (아직 db에 commit은 안함)
- 리더 서버에서 팔로우 서버들에게 update 요청을 broadcast 함.
- 팔로우 서버는 update를 수행하고 리더 서버에게 알림.
- 리더서버는 과반수 이상의 서버에서 update가 일어날경우 commit 요청을 보낸다. (이때 commit)
- 각 주키퍼 서버의 znode가 update되고 watcher를 등록해놓은 서버들은 event를 수신하여 data를 최신화한다.
- update 요청을 날린 client는 성공 응답을 받는다.
그림에서 볼 수 있듯이 주키퍼 cluster는 한개의 리더 서버와 여러개의 팔로워 서버로 이루어집니다. 그림에서 보면 각 client들은 리더,팔로우에 상관없이 아무 zookeeper server에 연결되어 있습니다. 따라서 update요청을 받는 서버는 리더 서버일 수도 있고 팔로우 서버일 수도 있습니다.
update명령은 무조건 리더 서버에서 수행됩니다. 따라서 팔로우 서버에서 zab명령을 통해 리더서버로 update 명령을 보냅니다. 리더서버의 znode가 수정됩니다. 이때 실제 db에는 반영이 안된상태입니다.
리더는 팔로우 서버들에게 업데이트 내용을 broadcast하고 팔로우 서버에서 update가 일어납니다. 그 후 팔로우들은 update 완료를 리더 서버에게 알리는데 이때 과반수 이상의 서버에서 업데이트가 일어나면 메모리 db에 해당 결과가 commit 됩니다. 이때 zab과정과 메모리 db접근과정은 모두 transaction 안에서 일어나므로 주키퍼는 원자성을 제공합니다.
각 주키퍼 서버의 노드가 업데이트 되었고 각 서버에 watcher를 달아놓은 client들은 update event가 발생했음을 알고 해당 data들을 최신화 시킴으로써 distribution이 마무리됩니다.
그리고 update 요청을 한 client는 성공 응답을 받습니다.
생길 수 있는 의문점
지금까지 주키퍼의 전체적인 그림을 살펴보았는데 다음과 같은 질문이 있을 수 있습니다.
주키퍼 서버가 죽으면 해당 서버를 watch하고 있던 client는 어떻게 되나?
-> 특정 서버에 문제가 생기면 주키퍼 내부적으로 다른 주키퍼 서버로 연결을 시도하고 이전 서버와 옮길 서버의 state가 같아질 때 까지 클라이언트는 요청을 할 수 없다. 따라서 client는 항상 같은 결과를 받을 수 있다.
그럼 리더서버가 죽으면 어떻게 되나?
-> 리더 선출 알고리즘을 사용해 리더를 다시 뽑는다. 이 과정은 0.5밀리초밖에 걸리지 않기 때문에 큰 문제가 되지 않는다.

댓글남기기