[데브인턴십 4기] 리팩터링을 할 때 생각해야 하는 것들
최영우업데이트:
배경
헬로우봇 스튜디오 서버는 헬로우봇에서 챗봇을 만들기 위해서 사용하는 사내 서버입니다. 워낙 오래전에 만들어지기도 했고, 외부에 오픈되지 않는 서버라 크게 신경쓰지 않는 코드는 점점 레거시화 됐습니다.
그리고 사내 에디터분들이 늘어나 사용자 수가 늘어날수록, 점점 다음과 같은 문제점들이 드러나기 시작했습니다.
- ‘라이브 챗봇 반영’ 기능로 인한 서버 장애가 많이 발생합니다.
- 라챗반은 무결성 검사를 위해서인지 사용자가 제작한 챗봇의 데이터를 실시간으로 서버에 한번 더 반영합니다.
- 다만 너무 과한 프로세스로 인해 서버에 장애를 많이 유발시킵니다.
- 헬로우봇 팀에는 숙련된 스프링 개발자가 없습니다.
- 반면 헬로우봇 스튜디오 서버는 Spring Framework 기반으로 작성됐기 때문에 유지보수에 어려움을 겪고 있습니다.
- 또한, 새로운 기능을 추가할 시 서버 개발자들에게 부담이 커집니다.
때문에 헬로우봇 스튜디오 서버의 재개발이 요구됐고, 이에 따라 저는 멘토인 손용기님과 함께 헬로우봇 스튜디오의 재개발을 맡아서 진행하게 됐습니다. 처음 인턴 온보딩 과제로 카테고리 API부터 시작해 메뉴 API에 이르기까지 총 4개의 API를 담당했습니다. 그림은 아래와 같습니다.
[New Studio porting]
|
|— 카테고리 API 포팅
|— 이미지 API 포팅
|— 메뉴 API 포팅
| |—— 태그 API 포팅
| |—— 프리미엄 스킬 API 포팅
| |—— 미리보기 이미지 API 포팅
|—— 검색 API 포팅
따라서 이 네 가지 API포팅을 진행하며 느꼈던, 생각했던 것들을 이번 포스트에 담아보고자 합니다. 사실 제가 온보딩 과제도 포팅이었고, 인턴 기간 동안 진행한 업무도 포팅이라 인턴 발표에서 중복되지 않는 내용을 위주로 다루고자 합니다. 아마, 온보딩 결과 발표회에서 조금 더 보태고, 마지막에 추가로 진행했던 DB migration 툴에 대한 요약이 추가될 것 같습니다.
거두절미하고 주제를 말씀드리자면, ‘코드를 작성할 때 고려해야되는 점’입니다.
클린 코드?
사실 제가 띵스플로우로 인턴을 오기 직전, 저는 학교에서 연결해주는 코칭 프로그램에서 spring 관련 코칭을 받고 있었습니다. 시니어 개발자님께 직접 짠 코드를 리뷰 받고, 스프링과 관련된 기초 지식들, 책이나 강의에서 보는 내용과 현업에서 실제로 어떻게 사용하는지 차이점 등을 배워볼 수 있는 좋은 기회였습니다.
해당 프로그램을 들으며 제는 클린코드에 관심을 갖기 시작했습니다.
(위의 링크와 여기 링크는 제가 클린코드 책을 보며 정리한 내용들을 기록하는 레포입니다. 출퇴근길에 가볍게 보기 좋게 정리하고 있습니다.)
마침 클린코드를 읽고 있던 제게 리팩토링은 실제 비즈니스 로직에 대한 고민보다는 클린코드를 공부하며 배웠던 내용들에 대한 고민을 집중할 수 있는 아주 효과적인 업무였습니다.
리팩토링을 할 때 고려할 점
때문에 이번 글에서는 코드의 클린함을 생각하며 개발하는 기준에 대해서 다루고자 합니다. 즉, 스스로 책을 읽으며 얻었던 지식들을 실제로 적용하면서 체득한 내용에 대해서 다룹니다.
목차는 다음과 같습니다.
그럼 하나씩 살펴보겠습니다.
1. 하나의 함수에선 하나의 추상화
하나의 함수에선 하나의 추상화 수준만 사용하는 것이 좋습니다. 잠깐, 여기서 추상화 수준이 뭘까요? 추상화 수준은 다음과 같이 정의할 수 있습니다.
추상화 수준이란?
특정 표현이 추상적인 개념에 가까운지 세부적인 구현에 가까운지의 정도 를 말합니다. 실제로 사칙연산이나 할당, 검증을 실제로 하는 로직은 세부적인 구현에 가깝고, ‘검증해라’, ‘할당해라’, ‘연산해라’ 등의 명령형 함수들을 호출해서 사용하는 것은 개념에 가깝다고 할 수 있습니다. 코드로 예시로 살펴봅시다.
낮은 추상화 수준
int directCount(List<int> inputList) { int result = 0; for (int i = 0; i < inputList.size(); i++) { result += inputList.get(i); } return result; }높은 추상화 수준
int processInput(UserReqDto userRequest) { validateRequest(userRequest); int result = directCount(userRequest.getInputList()); return new UserResDto(result); }
위의 예제 코드에서 볼 수 있듯 어떤 함수는 다른 함수를 호출하기만하여 그 함수들의 실행 순서를 결정하는 역할을 맡게 될 것이고, 어떤 함수는 구체적으로 어떻게 그 로직을 어떻게 구현할지 결정하게 됩니다.
이렇게 하나의 함수의 추상화 수준을 하나로 맞추는 것은 상당히 번거로운 일입니다. 하지만, 그 번거로운 과정이 끝나게 된다면, 아래와 같이 해당 함수의 내부에서 사용되는 함수들의 메소드 이름만 읽고도 이 함수가 어떤 기능을 하는지 쉽게 파악할 수 있게 됩니다.
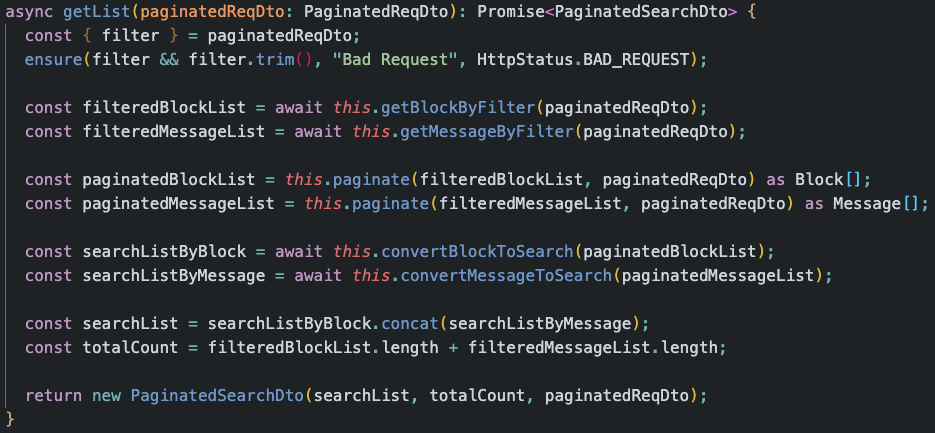
위 함수는 검색 API의 검색 서비스 로직입니다. 사용자가 설정한 조건에 맞춰 검색 결과를 내리는 함수인데, 대충 읽어봐도 어떤 흐름을 통해서 어떤 변수가 어떻게 저장되고, 어떤 값이 반환될지 예상할 수 있습니다.
반면 다음 코드를 한 번 봅시다.
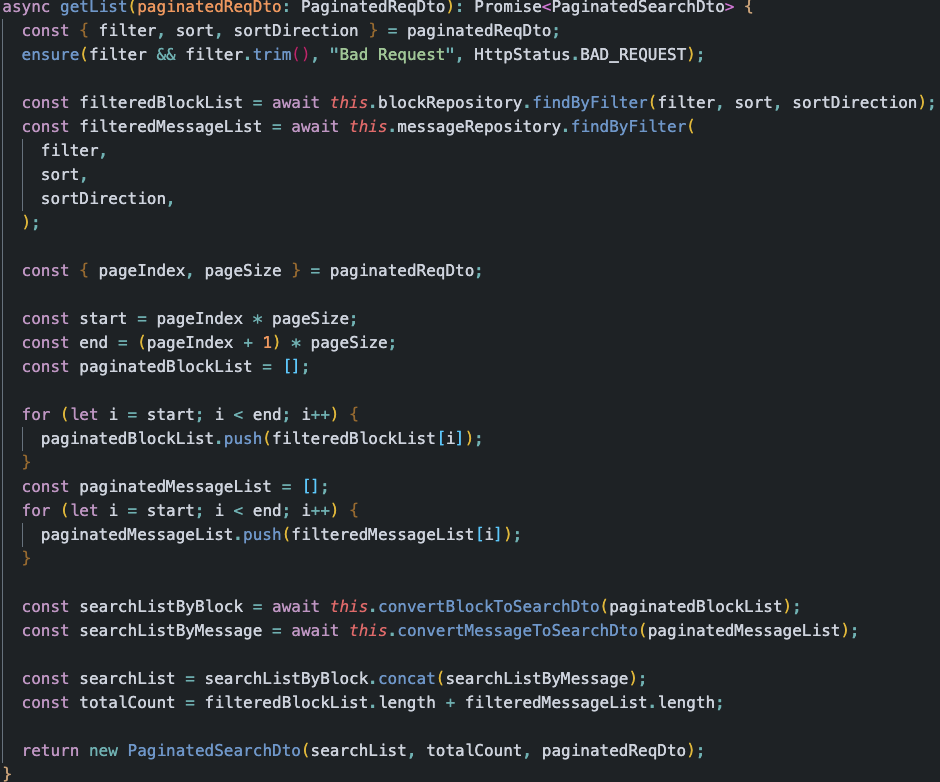
같은 동작을 하는 코드의 추상화 수준을 조금만 섞여다는 이유 하나만으로 이 함수가 어떤 역할을 하는 함수인지 파악하기 어려워졌습니다. 설령 자신은 한 눈에 파악할 수 있다고 하더라도, 자신과 협업하는 다른 프로그래머가 이해하기 힘들다면, 그건 좋은 코드라고 부르기 어려울 것 같습니다.
조금이라도 깨져있는 유리창을 깨는 것은, 그렇지 않은 유리창을 꺠는 것보다 죄책감이 덜하다고 합니다. 같은 이유로, 추상화 수준이 섞여있는, 한 번 지저분해진 코드는 다음 사람으로 하여금 더욱 코드를 더럽히기 쉽게 만듭니다.
따라서 코드를 작성하실 때는 최대한 추상화수준을 하나로 맞추시는게 좋습니다.
2. 신뢰할 수 있는 코드
신뢰할 수 있는 코드는 그 내부 로직을 깊게 들여다보지 않아도 그냥 잘 동작하겠거니 믿을 수 있는 코드를 의미합니다.
처음 보여드렸던 코드 내부에서 사용되는 메서드들은, 그 이름만 읽고도 어떤 식으로 동작할지 예상할 수 있습니다. 또한 실제로도 그렇게 동작합니다.
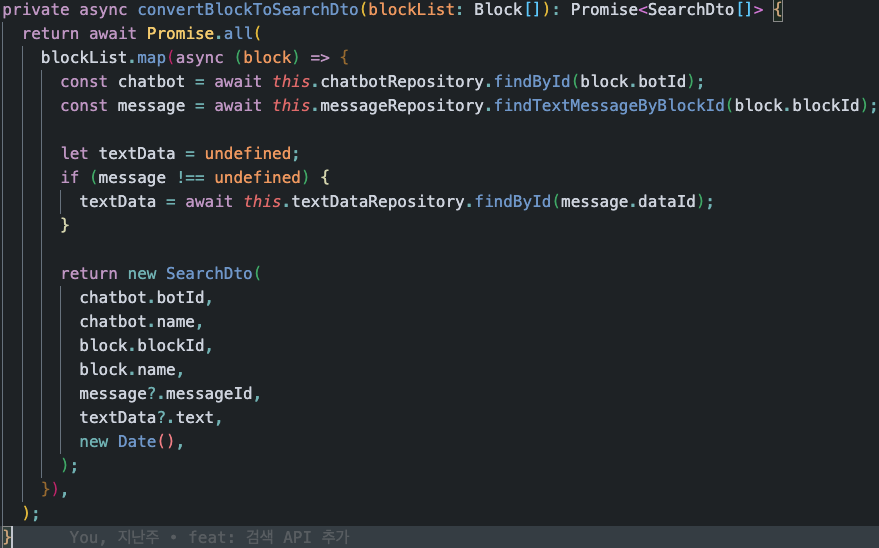
위 코드는 이름에서와 같이 입력받은 BlockList에 포함된 각각의 block들을 가지고 맞는 값들을 추출하여 하나씩 SearchDto를 만들어 반환합니다. 다만 단지 아래 한 줄만 보고서도 이런 내용이 유추되고, 실제로도 그 유추한 절차대로 작동합니다.
... = await this.convertBlockToSearchDto(blockList);
다음은 같은 코드에서 사용되는 다른 메서드인 paginate를 가져왔습니다.
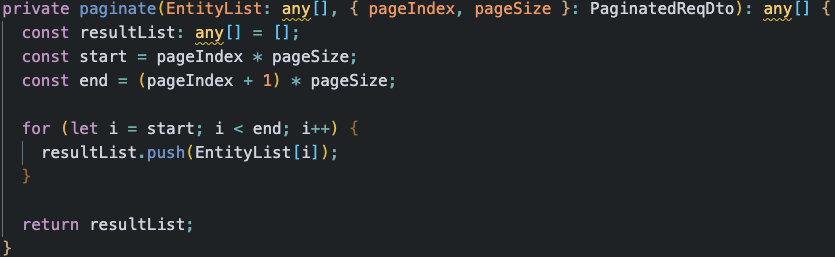
paginate라는 함수 또한, 그 이름에서 유추할 수 있듯 사용자의 paging 입력과 전체 목록을 받아 지정된 목록에서 해당 페이징이 가리키는 부분을 추출해 반환합니다. 한마디로 입력받은 List의 paginate된 결과를 반환합니다.
이번에도 역시 함수의 프로파일을 봐봅시다.
... = this.paginate(inputList, pagingReq);
단순히 프로파일을 보는 것만으로도 해당 메서드의 역할을 짐작할 수 있습니다.
이런식으로 함수의 이름만 보고도 그 함수가 어떤 역할을 하는지 예상을 할 수 있으며, 실제로 그 역할만을 하고, 다른 부가적인 영향을 만들어내지 않는, 즉 신뢰성이 높은 코드는 아주 중요합니다. 신뢰도가 높은 코드는 프로그래머로 하여금 코드를 빠르고 쉽게 재사용하도록 만들고, 이는 결국 높은 생산성으로까지 연결될 수 있기 때문입니다.
불신
doAboutPagingToInputList…? 무슨 함수지..? 가져다 써도 될까…? 하.. 로직을 또 하나하나 봐야겠구나. or 그냥 새로 처음부터 짜자…신뢰
Paginate? 페이징 함수구나! 우리 회사 사람이 짠 코드니까 신뢰해도 되겠지?
바로 가져다씀 -> 오류 없이 그대로 동작.
와! 재사용을 통해 시간을 아꼈다! (약 30분, 모이면 30시간)
코드를 작성시 메서드 명명법부터 시작해서 해당 메서드의 로직, 사이드이펙트 등을 충분히 생각해서 작성한다면, 그 코드는 신뢰할 수 있게 됩니다.
다음은 제가 생각하는 신뢰할 수 있는 코드를 작성하는 기준들입니다. 제 기준이 정답은 아니지만, 최소한 다른 사람은 이런 부분들을 고려하려 하는구나, 이런 것들도 고려할 수 있겠구나 정도로 귀엽게 봐주셨으면 합니다. (이런 것도 생각하면 좋아요~의 의견 제시는 언제나 환영입니다!!)
- 이름을 동작과 일치시키기
- 부가적인 동작 발생시키지 말기
- 하나의 함수에서는 하나의 동작만
- 함수로의 인자 전달 및 결과값 반환은 명시적으로 진행하기 (전역변수 사용 최소화)
- BAD:
await this.exampleDoing();- GOOD:
const exampleResult = await this.exampleDoing(exampleParams);
당장 생각나는 것은 여기까지입니다.
3. 재사용성을 고려한 일반화
재사용성을 고려한 일반화의 경우는 지난 온보딩 발표 때도 한 번 언급한 바 있습니다. 하지만, 일반화 자체는 생산성을 높이는 기준으로 일반화는 너무 중요한 것 같아서 다시 한 번 언급하게 됐습니다.
함수를 너무 일반화하는 것은 사용자로 하여금 이해하기 함수의 역할을 이해하기 힘들게 만들고 또 어떤 상황에서 사용할지 잘 파악하기 어렵게 만들기도 합니다. 하지만, 일반화되지 않은 함수는 특정된 하나의 목적만을 위해서 사용되어야 하고, 때문에 코드의 중복 및 생산성 하락을 야기하게 됩니다.
다시 가져온 페이지네이션 함수. 어떤 EntityList와 페이징 리퀘스트를 넣어도 반응할 수 있도록 만든, 일반화에 성공한 케이스라고 보시면 좋을 것 같습니다.
4. 코드의 작성은 신문 기사처럼
코드는 신문 기사를 작성하듯 만들어야한다고 합니다. 가장 먼저 추상적인 내용들이 나오고, 그 추상적인 내용들에 대해 구체적인 내용이 뒤따릅니다. 예를 들면 아래와 같습니다. (정말 간단한 예시)
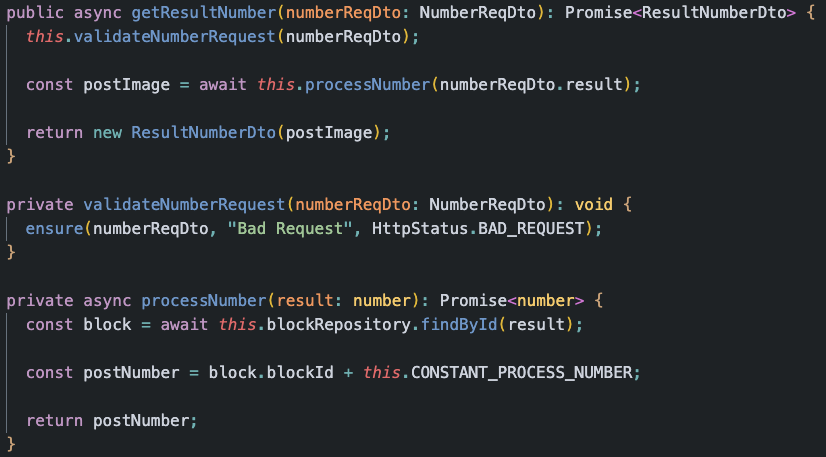
이렇게 추상화 수준이 높은 함수부터 차례로 낮아지는 함수를 작성한다면, 마치 신문 기사를 읽듯, 의식의 흐름대로 코드를 읽을 수 있게 됩니다. 예를 들어보자면 아래와 같은 과정을 밟을 수 있겠습니다.
- 아~ 사용자가 입력한 수에 대한 처리 결과를 가져오겠구나.
- 아~ 사용자가 입력한 수가 0인지 아닌지 검증하는구나.
- 아~ 사용자가 입력한 수는 이렇게 처리하는구나.
사실 이렇게 추상화가 위에서부터 아래로 내려가는 것은 아주 기초적인 개념이긴합니다. 때문에 가볍게 언급할 겸 마지막으로 추가했습니다.
첫 번째 후기
이쯤에서 발표의 흐름이 달라지기 때문에 미리 후기를 추가하려고 합니다.
가장 먼저 저는 마침 클린코드를 공부하고 있었기에 담당하게된 리팩토링 업무와 잘 연관지어 최대한 이론을 실전에 적용하려고 노력했습니다. 또한 제가 겪었던 프로젝트 설치 과정에서 겪었던 문제점들이나 어떻게 하는줄 몰라서 고생했던 부분들을 모두 문서로 남겨 다음 사람들에게는 같은 고생으로 인한 시간낭비를 줄인 것이 잘한 점이라고 생각합니다.
또한, 이번 업무를 진행하면서 이론으로만 배울 수 없었던 점들, 실제로 운영하고 있는 서비스를 이루는 코드들을 볼 수 있었기에 많은 것들을 배울 수 있었습니다. 하나의 간단한 서비스 로직에도 몇 중의 인증 과정을 거치는 것이 필요하다는 점 등은 혼자서 토이프로젝트를 진행하면서는 생각하기 힘든 부분이었습니다. 이외에도 프로젝트라는 배를 앞으로 나아가게 하기 위해서 필요한 여러 수고들과 과정 등까지도 많이 배울 수 있었습니다.
추가로 진행하고있는 DB Migration은 시간상의 문제로 아직 전부 완성하지는 못했지만, 앞으로 혼자 틈틈이 유지하면서 완성시켜보도록 하겠습니다.
부가 발표: 그래서 DB Migration은 뭔데?
4개의 API에 대한 포팅을 완료했지만, 테스트코드를 작성하지 않아서인지, 혹은 너무 빠른 속도로 끝나버려서 인턴십 기간이 7일가량 남았습니다.
때문에 새로운 API 포팅을 맡기엔 부족한 시간이라, 남는 시간에 DB 마이그레이션 툴을 한 번 제작해보는 것은 어떻겠냐고 제안해주셔서, 해당 부분을 진행하게 됐습니다.
현재 헬로우봇 스튜디오 서버의 DB는 NoSQL인 MongoDB를 사용하고 있습니다. Mongo에도 여러 장점이 있긴 하지만, 사용할수록 몇 가지 큰 단점들이 나타나고 있습니다. 간단하게 정리하자면 아래와 같습니다.
단점
- Join을 사용해 테이블 사이의 관계를 이용하는 것이 불가능합니다.
- Mongo 내에서 계층구조를 표현하기는 쉽지 않습니다.
- 이를 위해서는 관련된 collection을 모두 가져와 직접 비교해가면서 연관된 것을 추출한 뒤 표현해야 합니다.
- 데이터 구조의 변경이 용이하다는 장점은 외려 단점으로 다가오기도 합니다.
- 극단적으로, 한 API에서는 {userId, name}으로 추가되던 데이터가 다른 API에서는 {id, username}으로 저장 중일 수도 있습니다.
애초에 MongoDB는 검색을 빠르게 하는 용도로 사용됐어야 하지만, 저희 헬로우봇 스튜디오에서는 이를 RDB처럼 사용하고 있었습니다. 때문에 데이터가 쌓일수록 더욱 부각될 문제이며, 언젠간 해야할 마이그레이션이라면 뉴스튜디오 포팅이 진행중인 지금이 적기라고 생각돼 시작됐습니다.
최대한 빨리 진행해야했기 때문에 멀티스레딩을 사용할 생각을 했고, 데이터를 처리하는 과정은 ORM과 ODM을 사용하는 것이 가장 확실하다고 생각했습니다. 즉, 멀티 스레딩 인터페이스가 잘 갖춰져있고, 신뢰할 수 있는 튼튼하 ORM이 존재하는 언어로 진행하고자 했습니다. 쉽게 떠올릴 수 있듯 이는 Java였습니다.
Java에서도 특히 Spring을 사용해서 진행했는데 이유는 아래와 같습니다.
- Spring은 Spring-data-mongo와 spring-data-jpa등의 신뢰할 수 있는 ORM, ODM을 지원합니다.
- 기존 스튜디오 코드가 Spring으로 작성됐기 때문에 Entity를 추가하는 과정에서 발생하는 오버헤드를 최소화할 수 있습니다.
사실 두 번째 이유가 좀 컸는데, 발표를 제외하고 주어진 시간이 단 4일이었기 때문에 빠르게 만들었어야 합니다. (특히 스프링에 두 개의 다른 DB.. 심지어 NoSQL과 RDB..를 연결한 소스가 거의 전무했기 때문에… 저는 주말 이틀동안 거의 스프링 세팅에 사용했습니다..)
설계

프로젝트 설계는 다음과 같습니다. 최대한 제 생각을 제한하지 않도록 생각할 시간을 주신 멘토 분에 처음 이렇게 멀티 스레드를 사용해야되는 프로그램을 설계해봤습니다. (처음 설계한 것이므로 오류가 있을 수 있습니다.. 지적해주시면 감사하겠습니다.)
전체 프로세스를 간략하게 묘사하자면, ODM이 Mongo의 데이터를 읽어오고, Jpa Entity인 MigrationEntity로 변환합니다. 이후 ORM인 JPA가 해당 데이터를 저장합니다.
주의 깊게 보실 부분은 3. 멀티스레딩으로 진행하는 방법입니다. 결국 결정적인 프로세스를 담당하는 worker의 설계입니다. 크게 2개의 설계를 생각해봤습니다.
- 하나의 스레드가 entity를 읽고, 변환해서 저장하는 과정까지 한 번에 진행하는
All rounder모델 - reader는 읽어오기만 하고, writer는 변환해서 저장하기만 하는
Reader/Writer모델
각각에 대해서 떠올릴 수 있는 장단점을 정리하고, 용기님께 공유했습니다.
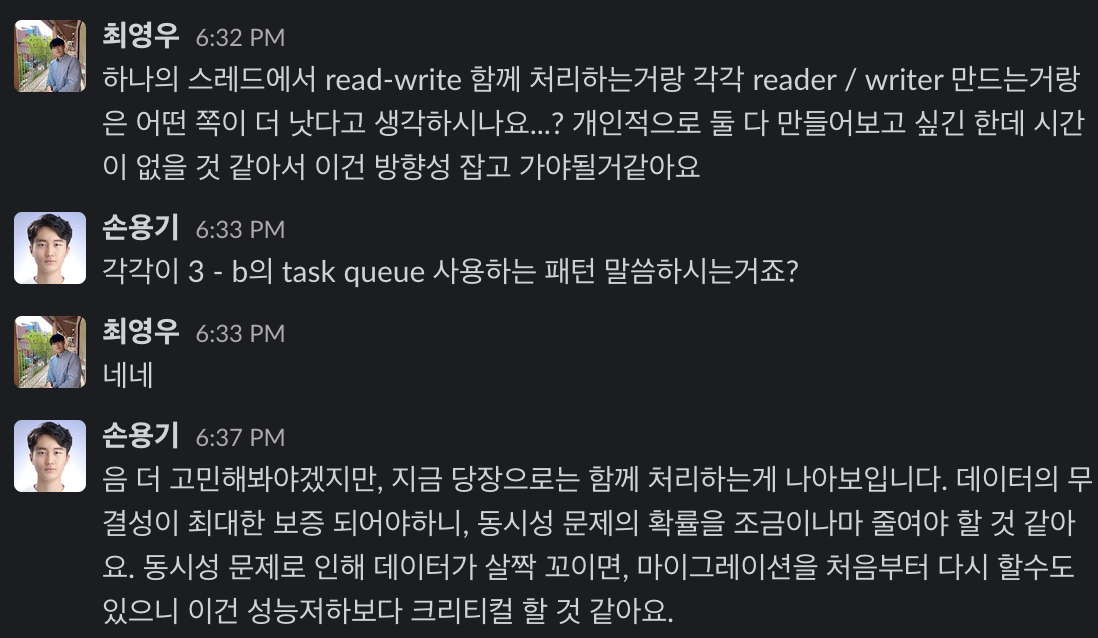
원래라면 reader/writer 모델로 작성하고, 동시성 문제를 최소화하도록 탄탄히 설계하는 것이 더 좋았을 것 같지만 (혼자 개발을 해보면서 이쪽으로도 개발해보려고 합니다.) 당장 지금은 거기까지 고민할 시간이 없으니 All Rounder 모델로 개발을 진행했습니다.
이건 마이그레이션 용도로 만들고 있는 마이그레이션 툴의 레포입니다.
https://github.com/cyw320712/DBMigrator
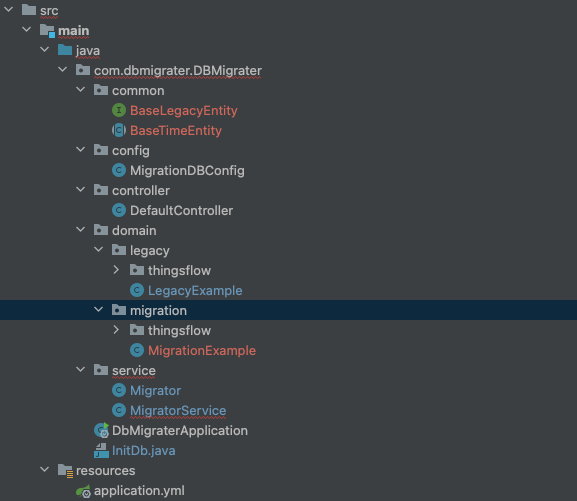
간단하게 구조를 먼저 그려보겠습니다.
[프로젝트 폴더]
- common
- 공통으로 사용되는 유틸들이 있는 폴더입니다.
- 특히 Entity scanning과정에서 최상위 추상화 Entity들을 제외하기 위해서 해당 폴더로 대피시켰습니다.
- config
- NoSQL과 RDB를 동시에 연동하기 위해선 Application.yml만으론 충분하지 않고, CustomDBConfig를 추가해줘야 합니다.
- 이외에도 지금 막힌 부분인 동적 레포지토리 빈 추가를 위한 설정 파일이 추가될 수도 있습니다.
- controller
- 스프링에서 서비스를 실행시키는 Trigger를 만들기 위해서 간단하게 root url로의 get 요청만 파싱해뒀습니다.
- 추후에 해당 migrator를 일반화에 성공한다면, 사용자가 엔티티 특성을 입력하고, 어떤 DB에서 어떤 DB로 옮길지, 어떤 converting 과정을 거칠지까지 웹에서 입력할 수 있습니다.
- domain
- 실제로 파싱할 Entity 파일들이 들어가있습니다. (Legacy -> Migration)
- thingsflow의 Entity들은 커밋하지 않도록 제외해뒀습니다.
- service
- 메인 마이그레이션 로직이 포함된 서비스입니다.
- 현재는 사용자가 생성한 MongoRepository, JpaRepository를 읽어와 등록하고 하나씩 처리하는 방식입니다.
- 지금 개선하는 부분은 MigratorService는 사용자가 저장한 Entity 목록만 읽어서 레포지토리를 동적으로 등록하도록 구현하려고 하고 있습니다.
프로젝트는 이런 구조로 만들어져있습니다. 메인 로직을 살펴보겠습니다.
준비과정
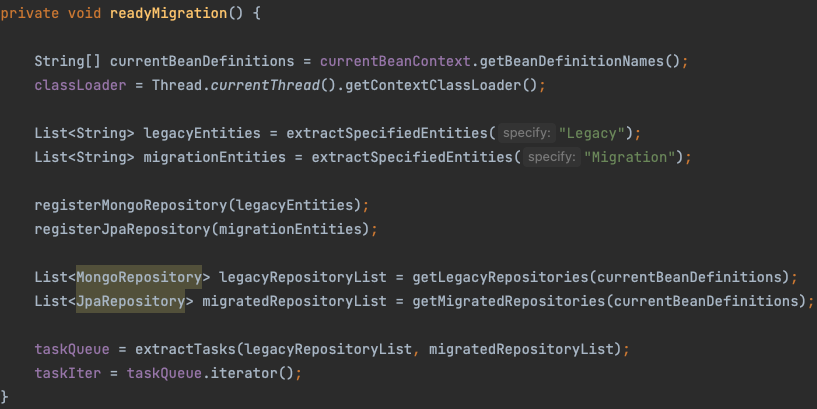
가장 먼저 마이그레이션을 준비하는 메소드입니다. extractSpecifiedEntities 함수는 지정한 단어가 포함된 엔티티 목록을 Domain 폴더에서 가져옵니다. 이후 추출한 Entity 목록을 통해 Repository를 동적으로 스프링 빈에 등록하고, 마지막으로 등록된 Repository들을 가져와서 taskQueue에 담아주면 준비가 완료됩니다.
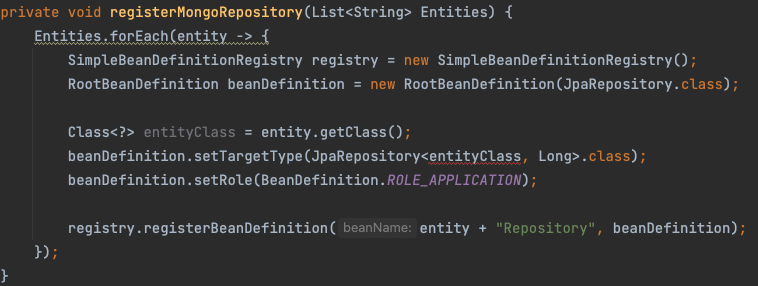
하지만 보실 수 있듯 JpaRepository에 등록하기 위해서는 명시적인 ClassType이 필요합니다… 또한 JpaRepository가 추상 인터페이스라 인스턴스화 할 수 없다는 벽 또한 마주하고 있습니다. 인턴십이 종료되면 JpaRepository나 MongoRepository가 어떤 과정을 거쳐서 스프링 내부에서 인스턴스화 되는지 파악하고, 해당 과정을 동일하게 거쳐서 등록하려고 합니다.
사실 그냥 사용자에게 Repository 코드까지 작성하도록 구현해도 괜찮습니다. 하지만, 해당 프로젝트에서 사용하는 JpaRepository와 MongoRepository의 method는 findAll과 save로 한정됩니다. 때문에 해당 레포지토리 코드를 들어가면 텅 빈 코드를 마주하게 됩니다.


이런 코드가 중복되는 것은 그냥 수긍하실 수도 있습니다. 하지만 사용자가 마이그레이션 하려는 Entity마다 모두 저런 코드를 생성해줘야하는 것은 분명한 단점으로 다가옵니다.
당장 저희 헬로우봇 스튜디오에서 마이그레이션하고자 하는 Entity(Table) 개수만해도 57개였습니다. legacy와 migration 양쪽 모두에 해당 코드를 생성해줘야 하므로 총 114개의 사실상 비어있는 파일을 생성해줘야하는 번거로움이 있습니다.
어쨋든 지금은 저렇게 레포지토리를 직접 생성해주면 동작하도록 구현중입니다. 메모리나 각 테이블별 워크로드를 조사해 각각의 스레드에 할당할 작업을 분배하는 것도 추후에 작업으로 예정되어 있습니다.
마이그레이션
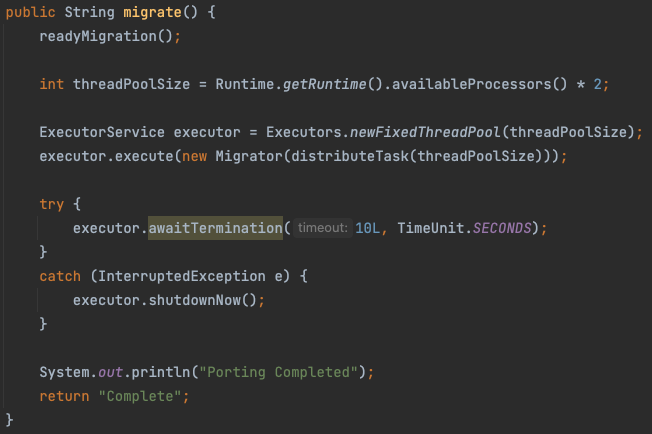
사용자가 localhost:8080/으로 get요청을 보내면 간단히 마이그레이션 서비스의 이 migrate함수를 호출합니다. 그럼 해당 함수는 readyMigration을 호출하고, 현재 프로세서에서 생성가능한만큼의 스레드를 생성합니다.
이후 추가로 읽기 -> convert -> 저장하기 과정을 진행하는 Migrator 클래스를 쓰레드별로 할당시키고, 완료되면 완료됐다고 Complete 메세지를 띄워줍니다. (사실 저 과정도 그냥 10초 뒤에 완료됐다고 뜨고 백그라운드에서 작업은 계속 진행하던데… 이부분에는 디버깅이 필요합니다.)
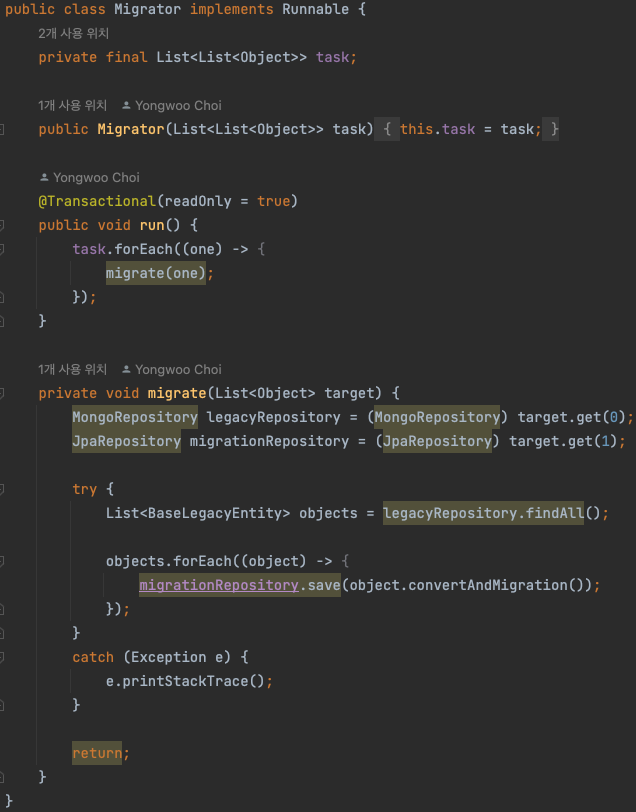
간단한 Migrator Class입니다. Task가 담긴 queue를 넣으며 클래스를 선언하고, 각각의 thread는 task에서 각각의 레포지토리를 가져와 읽고 convert하고 저장합니다. 이렇게 메인 코드가 단순화될 수 있는 배경에는 추상화가 있습니다.
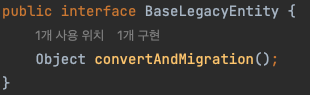
간단한 추상화 인터페이스를 생성하고, 각 Legacy Entity는 이 interface의 구현체로써 존재합니다.
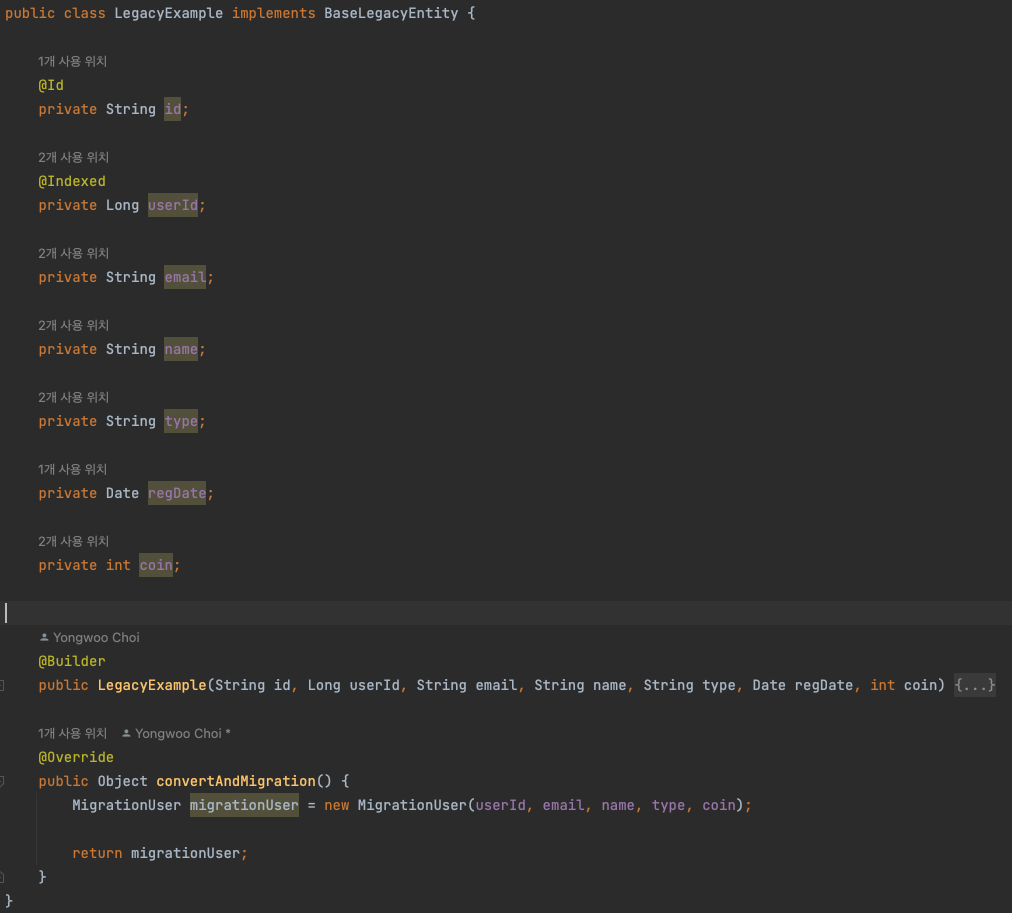
이후 각 Entity에서는 위 인터페이스에 대한 Convert 함수를 자신의 데이터에 맞게 구현합니다. 이렇게 각 Entity에 구현된 convert 함수를 사용하기만 하면, 특정 Entity에 특성화된 migrate 함수를 작성할 필요 없이 일반화된 함수로 구현할 수 있게 되는겁니다!
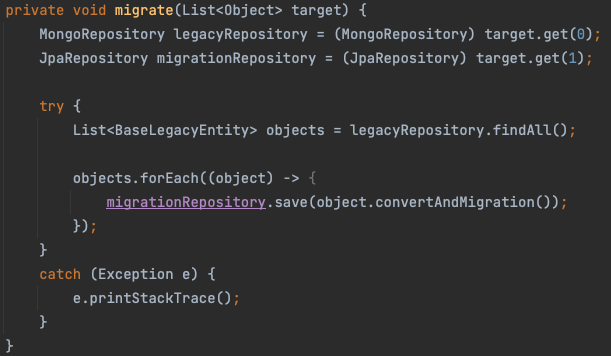
위 코드를 보시면 task에서 가져온 임의의 레포지토리를 통해서 데이터를 findAll로 가져오고, save할 뿐 Entity에 맞춰서 어떤 작업을 추가로 수행하지는 않습니다. 그렇게 Save까지 완료되면 모든 과정이 완료됩니다.
아쉬운 점이라면, 당장 시간이 부족해 메모리가 어느 정도까지 버틸 수 있는지 파악하지 못했고, 때문에 한 번에 가져와 한 개씩 save하고 있다는 점입니다. 현재 더미 데이터로 테스트해본 결과 1만개의 간단한 User Entity에 대해서 30초 정도의 시간이 소요됩니다. 만약 한 1000개씩만이라도 bulk insert하도록 변경한다면 획기적인 시간 단축을 구현할 수 있을 것이라 생각됩니다.
또한 현재 레포지토리를 동적으로 생성해서 빈에 등록하는 과정에서 막혀있는데 워낙 소스가 없어서 이게 가능한건지조차 모르고 있습니다. 우선은 스크립트로 레포지토리를 생성하고, 추후에 코드 없이도 동적으로 등록할 수 있도록 수정하려고 합니다.
두 번째 후기
DB 마이그레이션은 사실 aws 등에서 지원하는 20만원 상당의 서비스가 이미 존재하기 때문에 그걸 이용하면 되긴 합니다. 그럼에도 불구하고 직접 멀티스레딩을 사용하는 프로그램을 제작하고, 수백만 건의 데이터에 대해서 직접 사용해볼 일이 많지는 않았기에 정말 소중한 경험을 얻을 수 있었습니다.
아직 남아있는 구현 요구사항들은 아래와 같습니다.
- 메모리가 터지지 않도록 한 번에 가져오고, 변환해서 저장하는 데이터의 양을 찾고 그 안에서 프로세스가 동작하도록 구현합니다.
- 레포지토리 및 엔티티를 사용자의 입력에 맞춰 동적으로 생성해 스프링 빈에 등록하고, 사용할 수 있도록 구현합니다.
- DB connection의 개수에 맞춰 스레드를 생성할 수 있도록 수정합니다.
- 모니터링 스레드 등을 추가하여 데이터의 무결성에 문제가 발생하는 일이 없도록 수정합니다.
- 사용자가 지정한 DBMS에 맞게 알아서 레포지토리를 수정해 추가합니다.
- 사용자가 지정한 convert 로직에 맞춰 데이터를 수정할 수 있도록 합니다.
… 등의 다양한 추가 기능을 구현할 수 있습니다. 비록 이제는 남은 인턴 기간이 없기 때문에 더이상 진행할 수 없지만, 퇴사 이후로도 홀로 유지보수해 쓸만한 툴이 될 수 있도록 만들어보겠습니다.

댓글남기기